Dapr – a Severless runtime for distributed applications
A microservice architecture allows you to tackle scalability problems, high availability and quick time-to-market settlement. However, your teams need to be warned about this type of architecture. Indeed, microservices needs high development rigor and good dependency management, and so maintain multiple applications with microservices can be heavy and complex.
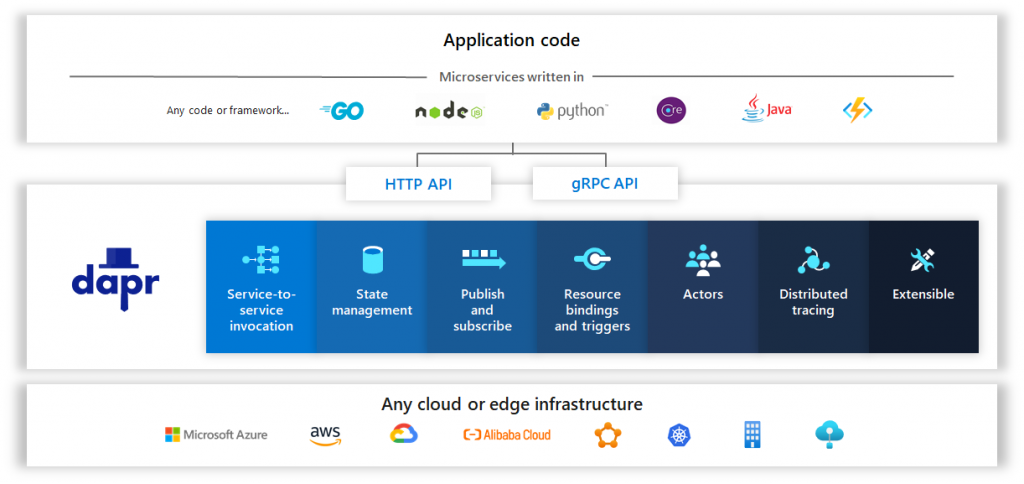
Dapr is a tool for reducing this kind of complexity induced by distributed applications. It’s part of this sort of tools, like Kubernetes, that abstract all the interactions between your dependencies and the external world of your IS. The key difference between Dapr and Kubernetes is that the last one acts at the system level, while Dapr acts on the application level. It implements a complete runtime where your applications can run safely, whatever the language, and where they access to multiples APIs facilitating some aspects of a complex microservice architecture: inter-service calls, queue management, state management …
A little about architecture …
Dapr is all about abstractions. Indeed, every microservice platform needs classic elements like state management or Pub/Sub mechanisms, and Dapr is here to simplify interactions between your applications and these services. Dapr is based on Docker images, and so it encapsulates some of the famous infrastructure services like Redis or Service Bus to be pluggable with applications. These tools can be reached with standard HTTP and/or gRPC calls from within applications with your favorite languages.
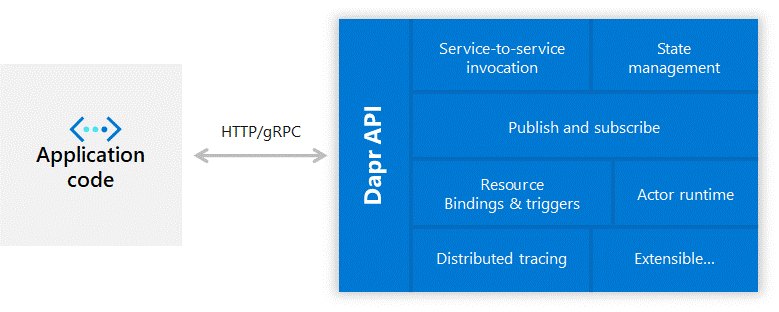
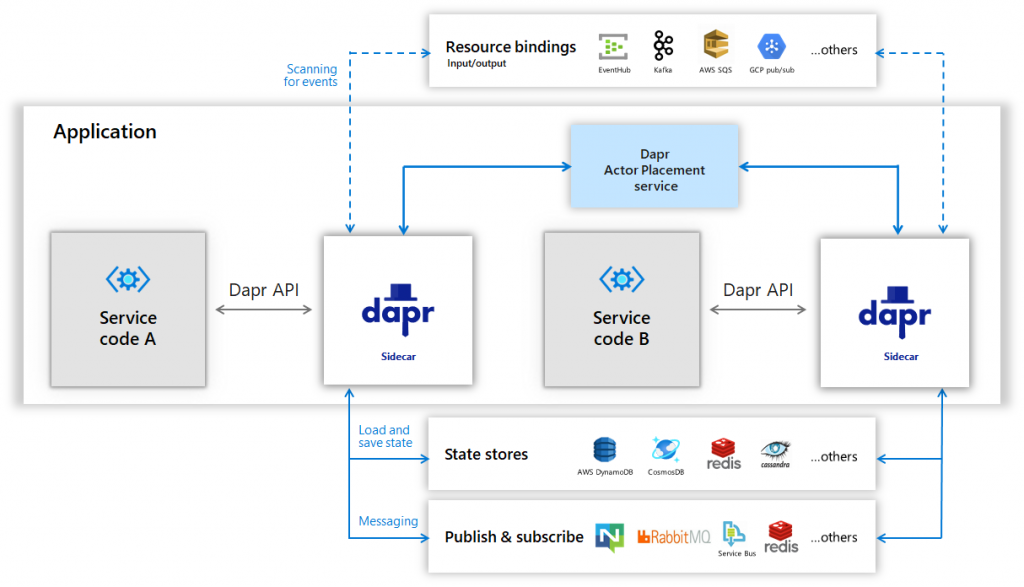
Dapr run as a standalone process that interacts with your application to perform some actions. For example, if you want to store some objects as a persistent state for your application, you will first call the Dapr API (HTTP or gRPC), and Dapr will subsequently call the right system with the state management system and store your object. Here is the architecture process when you run Dapr in local mode :
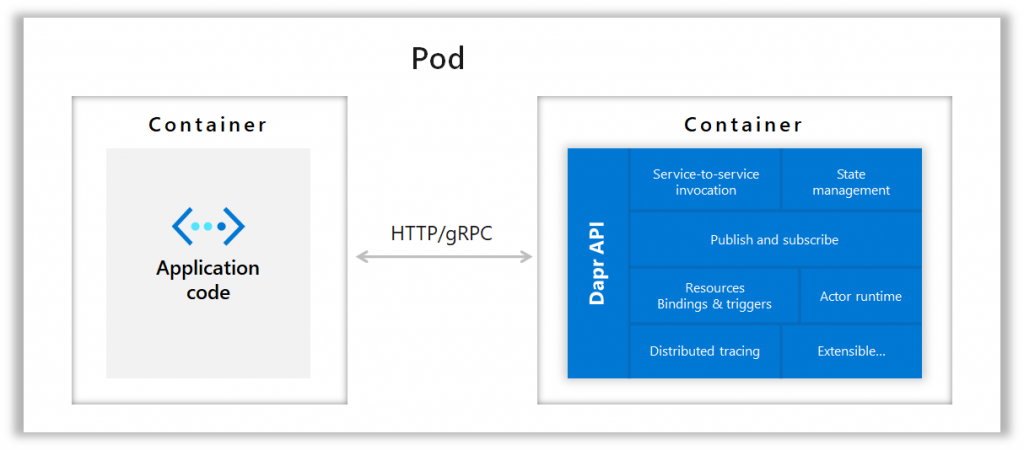
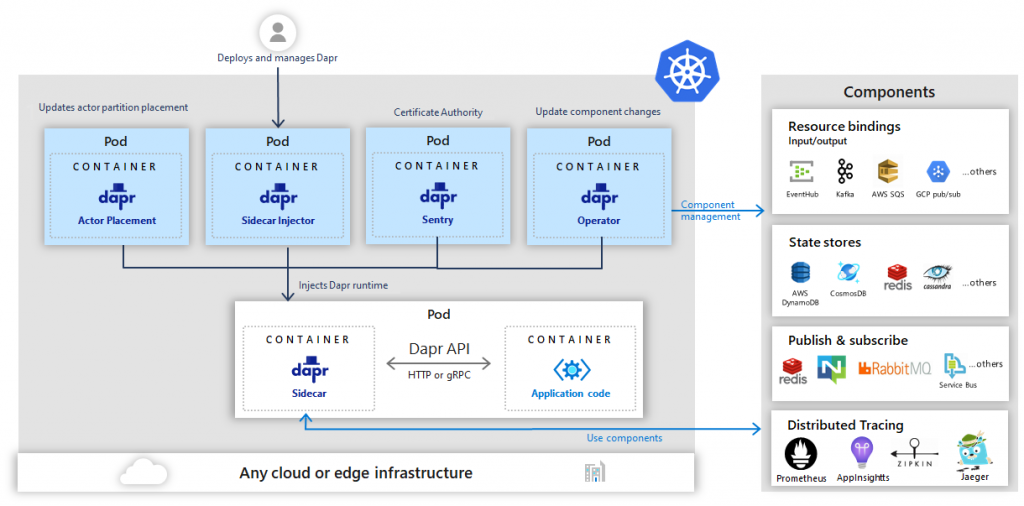
Here is the version with Kubernetes :
The Dapr platform is built around the concept of building blocks. A building block is a single unit feature usable by your application to perform some actions. For example, state management is a building block. Here is the list of building blocks available of the moment of the writing of the article (version 0.6) :
- Service Invocation : service-to-service invocation through method calls with retries. Each service can be automatically discovered by Dapr ;
- State Management : key/value pairs store including Azure CosmosDB, AWS DynamoDB or Redis ;
- Publish and Subscribe Messaging : Publishing events and subscribing to topics ;
- Resource Bindings : resource bindings and triggers with event-driven approach ;
- Distributed tracing : easy logging and event tracing through all Dapr workflows ;
- Actors : actor model pattern implementation that make concurrency simple with method and state encapsulation. Actors are orchestrated by Dapr with many capabilities like timer, activation/desactivation and reminders.
In local mode, each running service launches a Dapr runtime process aside of the application, and use a Redis Docker image to use state management and Pub / Sub building block.
At the same time, Dapr can be configured to run in Kubernetes. Dapr will configure his services to run into Pods, and runs as a side-card container in the same pod as the service. This container will provide notifications of Dapr components updates.
A Dapr project structure
Dapr is pluggable with any projects : you only need to install the Dapr CLI, and it will automatically encompass your application into the Dapr runtime. The main commands of the CLI are :
- init : initializes the Dapr installation into your local machine, or Kubernetes if –kubernetes is specified ;
- run : runs the specified application into the Dapr runtime ;
- stop : stops the specified application ;
- list : lists all applications that are currently running ;
- invoke : calls a specified API exposed by the service ;
- publish : publishes an event to the pub/sub mechanism (whatever it is configured into the runtime, Dapr completely abstracts this part) ;
When you launch the command dapr run in your local environment, Dapr automatically creates YAML config files for 2 standard building blocks:
- pubsub.yaml : a Redis component with Pub / Sub functionality ;
- statestore.yaml : a Redis cache for store management.
The Pub/Sub config file looks like this
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: messagebus
spec:
type: pubsub.redis
metadata:
- name: redisHost
value: localhost:6379
- name: redisPassword
value: ""
What does it say ? It tells Dapr to create a Redis cache configuration for pub/sub commands, configures the cache to be reachable at localhost:6379 with no password. This configuration should only be used in local mode. These few lines of code are enough for Dapr to create your building block. Of course, this configuration would be improved in future development of Dapr.
The second file looks like this :
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: statestore
spec:
type: state.redis
metadata:
- name: redisHost
value: localhost:6379
- name: redisPassword
value: ""
- name: actorStateStore
value: "true"
The configuration is almost the same, but it includes the actorStateStore section. The parameter indicates Dapr that the store management mechanism should be used like an actor building block. This means that only one thread can be active inside an actor object’s code at any time. Turn-based access greatly simplifies concurrent systems as there is no need for synchronization mechanisms for data access.
These simple config files allows your application to use state management and pub/sub building blocks through Dapr mechanisms. For example, into the same project, we have:
- A Node project which acts as a server for simple CRUD operations;
- A Python project as a client which calls the server each second for posting data;
The project can be found into the Dapr sample repository : https://github.com/dapr/samples.
To launch your Node app, you only have to use this command :
dapr run --app-id nodeapp --app-port 3000 --port 3500 node app.js
The app-id allows Dapr to identify your app with a unique id, the app-port is the port which Dapr can access your app through, and the port option defines the port of Dapr. After all the options, you just have to specify the command to launch your app, here is node app.js.
To check if your app is up and running, you can use an HTTP client (Curl, Postman …) and run this query :
POST http://localhost:3500/v1.0/invoke/nodeapp/method/neworder
You can directly use a Dapr command to post your command :
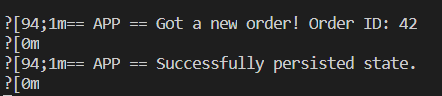
dapr invoke --app-id nodeapp --method neworder --payload "{\"data\": { \"orderId\": \"41\" } }"
Your app generates logs when it receives a new HTTP call, and Dapr relays the logs into your console. When you launch the command, you can see your app logs appear :
The code below shows how the Node app in interacting with Dapr to store the order. It only calls the Dapr URL (http://localhost:3500/v1.0/state/statestore) and posts the payload to be stored into the Redis cache.
app.post('/neworder', (req, res) => {
const data = req.body.data;
const orderId = data.orderId;
console.log("Got a new order! Order ID: " + orderId);
const state = [{
key: "order",
value: data
}];
fetch(stateUrl, {
method: "POST",
body: JSON.stringify(state),
headers: {
"Content-Type": "application/json"
}
}).then((response) => {
if (!response.ok) {
throw "Failed to persist state.";
}
console.log("Successfully persisted state.");
res.status(200).send();
}).catch((error) => {
console.log(error);
res.status(500).send({message: error});
});
});
With a simple HTTP call you can achieve a state management operation through the Dapr abstraction layer.
After checking that our Node application is working correctly, we can run the Python program. This small application calls the Node app periodically to persist state into Redis. The Python application uses the call service mechanism of Dapr to call the Node service through this URL :
http://localhost:3500/v1.0/invoke/nodeapp/method/neworder
Open a new command prompt and use this command to launch the Python app (Python should be installed into your machine):
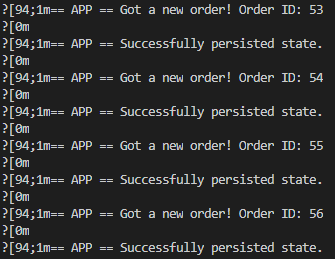
dapr run --app-id pythonapp python app.py
If you return to the first prompt, you’ll see new logs coming from the Node application telling that new orders are created and stored into the Redis cache.
Thanks to Dapr, we are able to make a communication between 2 microservices through a common abstraction layer. In conclusion, Dapr allows you to :
- Integrate easily an application into a complex microservices architecture;
- Use standard communication channels between services;
- Operate services with common building blocks (state management, pub/sub …);
- Wrap your services into small atomic process units easily switchable;
- Use as many languages as you want;
What about Tye ?
Tye is a tool that makes developing, testing, and deploying microservices and distributed applications easier. Project Tye includes a local orchestrator to make developing microservices easier and the ability to deploy microservices to Kubernetes with minimal configuration. The project is here : https://github.com/dotnet/tye.
Tye focuses on .NET project and makes easier for you to launch .NET microservices in your local environment with a single command line :
tye run
tye run
This tool uses your SLN project file to find all your projects and run it together. You can launch a project separately (inside the project folder) or all together with your SLN file. Tye uses a separate YAML config file if you want to run this tool into your CI/CD pipeline. For example, if you use the command line tye init, the tool generates this file tye.yaml :
name: microservice services: - name: frontend project: frontend/frontend.csproj - name: backend project: backend/backend.csproj
This file references all your project based on your SLN file. The YAML allows you to specify more settings apart of the SLN file, like the registry you want to use.
registry: <registry_name>
The schema for the YAML file can be found here : https://github.com/dotnet/tye/blob/master/src/schema/README.md.
Tye fits perfectly with Dapr as a local orchestrator of your microservices. Dapr is here to perform a loosely-coupled architecture, meanwhileTye is here to orchestrate the launching, debugging and deployment of all your services. Inside the Tye Github project you can find a Dapr sample. This project includes a YAML file with all the .NET project referenced. Inside this file, you noticed the section about Dapr :
extensions: - name: dapr log-level: debug
With only these lines, Tye launches all your projects through the Dapr command line.
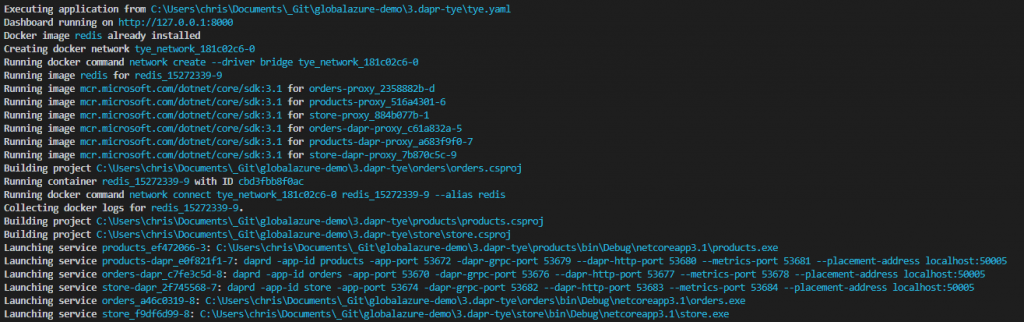
The Tye dashboard shows you all the containers launched, and you can see that Dapr container are launched aside of your services containers.
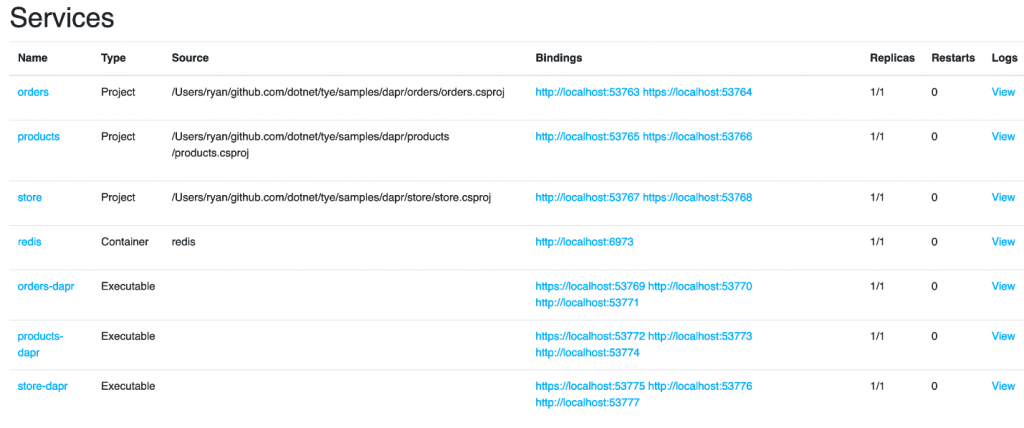
The redis acts here as a pub/sub and state management component.
Conclusion
Theses two projects are currently under development and should not be used for production environment. But this looks promising! We can use Dapr to easily simplify our architecture and build very atomic loose-coupled microservices, and in the same time we have Tye to help us with our local development, debugging and deployment. All these tools can be used separately or together, but they definitely help us as developers for microservices development.